Financial theory requires correlation to be constant (or, at least, known and nonrandom). Nonrandom means predictable with waning sampling error over the period concerned. Ellipticality is a condition more necessary than thin tails, recall my Twitter fight with that non-probabilist Clifford Asness where I questioned not just his empirical claims and his real-life record, but his own theoretical rigor and the use by that idiot Antti Ilmanen of cartoon models to prove a point about tail hedging. Their entire business reposes on that ghost model of correlation-diversification from modern portfolio theory. The fight was interesting sociologically, but not technically. What is interesting technically is the thingy below.
How do we extract sampling error of a rolling correlation? My coauthor and I could not find it in the literature so we derive the test statistics. The result: it has less than \(10^{-17}\) odds of being sampling error.
The derivations are as follows:
Let \(X\) and \(Y\) be \(n\) independent Gaussian variables centered to a mean \(0\). Let \(\rho_n(.)\) be the operator.
\(\rho_n(\tau)= \frac{X_\tau Y_\tau+X_{\tau+1} Y_{\tau+1}\ldots +X_{\tau+n-1} Y_{\tau+n-1}}{\sqrt{(X_{\tau}^2+X_{\tau+1}^2\ldots +X_{\tau+n-1}^2)(Y_\tau^2+Y_{\tau+1}^2\ldots +Y_{\tau+n-1}^2)}}.\)\
First, we consider the distribution of the Pearson correlation for \(n\) observations of pairs assuming \(\mathbb{E}(\rho) \approx 0\) (the mean is of no relevance as we are focusing on the second moment):
\(f_n(\rho)=\frac{\left(1-\rho^2\right)^{\frac{n-4}{2}}}{B\left(\frac{1}{2},\frac{n-2}{2}\right)},\)
with characteristic function:
\(\chi_n(\omega)=2^{\frac{n-1}{2}-1} \omega ^{\frac{3-n}{2}} \Gamma \left(\frac{n}{2}-\frac{1}{2}\right) J_{\frac{n-3}{2}}(\omega ),\)
where \(J_{(.)}(.)\) is the Bessel J function.
We can assert that, for \(n\) sufficiently large: \(2^{\frac{n-1}{2}-1} \omega ^{\frac{3-n}{2}} \Gamma \left(\frac{n}{2}-\frac{1}{2}\right) J_{\frac{n-3}{2}}(\omega ) \approx e^{-\frac{\omega ^2}{2 (n-1)}},\) the corresponding characteristic function of the Gaussian.
Moments of order \(p\) become:
\(M(p)= \frac{\left( (-1)^p+1\right) \Gamma \left(\frac{n}{2}-1\right) \Gamma \left(\frac{p+1}{2}\right)}{2 \left(\frac{1}{2},\frac{n-2}{2}\right) \Gamma \left(\frac{1}{2} (n+p-1)\right)}\)
where \(B(.,.)\) is the Beta function. The standard deviation is \(\sigma_n=\sqrt{\frac{1}{n-1}}\) and the kurtosis \(\kappa_n=3-\frac{6}{n+1}\).
This allows us to treat the distribution of \(\rho\) as Gaussian, and given infinite divisibility, derive the variation of the component, sagain of \(O(\frac{1}{n^2})\) (hence simplify by using the second moment in place of the variance):.
\(\rho_n\sim \mathcal{N}\left(0,\sqrt{\frac{1}{n-1}}\right).\)
To test how the second moment of the sample coefficient compares to that of a random series, and thanks to the assumption of a mean of \(0\), define the squares for nonoverlapping correlations:
\(\Delta_{n,m}= \frac{1}{m} \sum_{i=1}^{\lfloor m/n\rfloor} \rho_n^2(i; n),\)
where \(m\) is the sample size and \(n\) is the correlation window. Now we can show that:
\(\Delta_{n,m}\sim \mathcal{G}\left(\frac{p}{2},\frac{2}{(n-1) p}\right),\)
where \(p=\lfloor m/n\rfloor\) and \(\mathcal{G}\) is the Gamma distribution with PDF:
\(f(\Delta)= \frac{2^{-\frac{p}{2}} \left(\frac{1}{(n-1) p}\right)^{-\frac{p}{2}} \Delta ^{\frac{p}{2}-1} e^{-\frac{1}{2} \Delta (n-1) p}}{\Gamma \left(\frac{p}{2}\right)},\)
and survival function:
\(S(\Delta)=Q\left(\frac{p}{2},\frac{1}{2} \Delta (n-1) p\right),\)
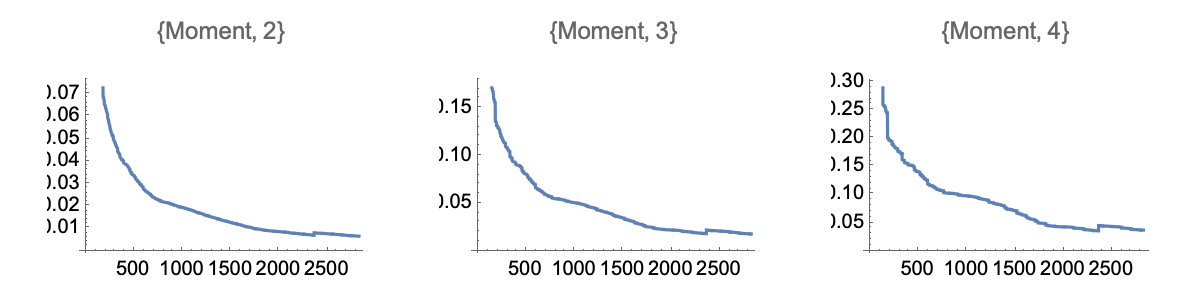
which allows us to obtain p-values below, using \(m=714\) observations (and using the leading order $O(.)$:

Such low p-values exclude any controversy as to their effectiveness cite{taleb2016meta}.
We can also compare rolling correlations using a Monte Carlo for the null with practically the same results (given the exceedingly low p-values). We simulate \(\Delta_{n,m}^o\) with overlapping observations:
\(\Delta_{n,m}^o= \frac{1}{m} \sum_{i=1}^{m-n-1} \rho_n^2(i),\)
Rolling windows have the same second moment, but a mildly more compressed distribution since the observations of \(\rho\) over overlapping windows of length \(n\) are autocorrelated (with, we note, an autocorrelation between two observations \(i\) orders apart of \(\approx 1-\frac{1}{n-i}\)). As shown in the figure below for \(n=36\) we get exceedingly low p-values of order \(10^{-17}\).