
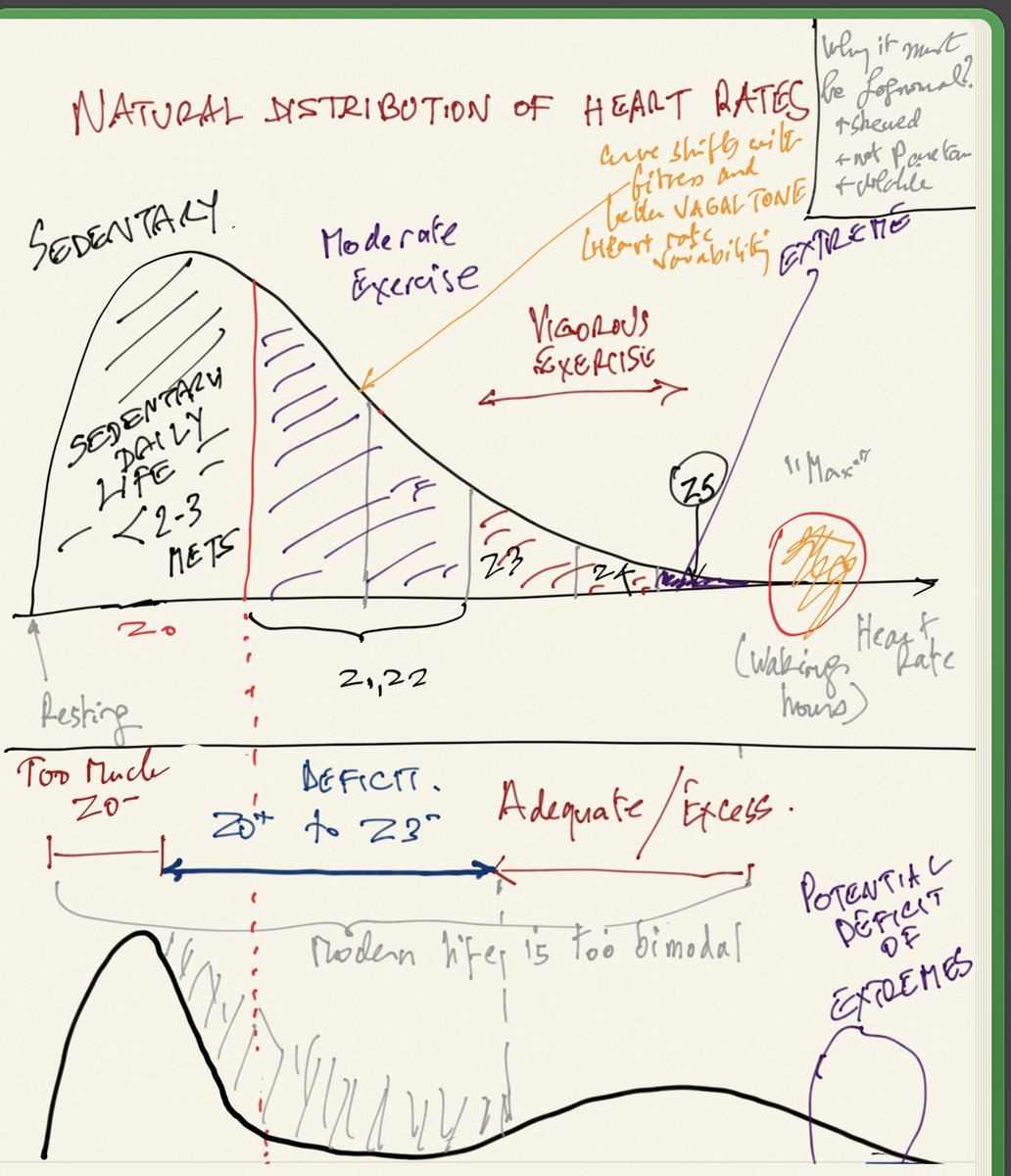
Heart rates must be Lognormal in distribution. Simply, it is not possible to have a negative heart rate and at low variance (and a mean > 6 standard deviations away from 0), the lognormal behaves like a normal.
Incidentally I failed
Heart rates must be Lognormal in distribution. Simply, it is not possible to have a negative heart rate and at low variance (and a mean > 6 standard deviations away from 0), the lognormal behaves like a normal.
Incidentally I failed
Background: We’ve discussed blood pressure recently with the error of mistaking the average ratio of systolic over diastolic for the ratio of the average of systolic over diastolic. I thought that a natural distribution would be the gamma and cousins, but, using the Framingham data, it turns out that the lognormal works better. For one-tailed distribution, we do not have a lot of choise in handling higher dimensional vectors. There is some literature on the multivariate gamma but it is neither computationally convenient nor a particular good fit.
Well, it turns out that the Lognormal has some powerful properties. I’ve shown in a paper (now a chapter in The Statistical Consequences of Fat Tails) that, under some parametrization (high variance), it can be nearly as “fat-tailed” as the Cauchy. And, under low variance, it can be as tame as the Gaussian. These academic disputes on whether the data is lognormally or power law distributed are totally useless. Here we realize that by using the method of dual distribution, explained below, we can handle matrices rather easily. Simply, if \(Y_1, Y_2, \ldots Y_n\) are jointly lognormally distributed with a covariance matrix \(\Sigma_L\), then \(\log(Y_1), \log(Y_2), \ldots \log(Y_n)\) are normally distributed with a matrix \(\Sigma_N\). As to the transformation \(\Sigma_L \to \Sigma_N\), we will see the operation below.
Let \(X_1=x_{1,1},\ldots,x_{1,n}, X_2= x_{2,1},\dots x_{2,n}\) be joint distributed lognormal variables with means \(\left(e^{\mu _1+\frac{\sigma _1^2}{2}}, e^{\mu _2+\frac{\sigma _2^2}{2}}\right)\) and a covariance matrix
\(\Sigma_L=\left(\begin{array}{cc}\left(e^{\sigma _1^2}-1\right) e^{2 \mu _1+\sigma _1^2}&e^{\mu _1+\mu _2+\frac{\sigma _1^2}{2}+\frac{\sigma _2^2}{2}}\left(e^{\rho \sigma _1 \sigma _2}-1\right)\\ e^{\mu _1+\mu _2+\frac{\sigma _1^2}{2}+\frac{\sigma _2^2}{2}}\left(e^{\rho \sigma _1 \sigma _2}-1\right)&\left(e^{\sigma _2^2}-1\right) e^{2 \mu _2+\sigma _2^2}\end{array}\right)\)
allora \(\log(x_{1,1}),\ldots, \log(x_{1,n}), \log(x_{2,1}),\dots \log(x_{2,n})\) follow a normal distribution with means \((\mu_1, \mu_2)\) and covariance matrix
\(\Sigma_N=\left(\begin{array}{cc}\sigma _1^2&\rho \sigma _1 \sigma _2 \\ \rho \sigma _1 \sigma _2&\sigma _2^2 \\ \end{array}\right)\)
So we can fit one from the other. The pdf for the joint distribution for the lognormal variables becomes:

\(f(x_1,x_2)= \frac{\exp \left(\frac{-2 \rho \sigma _2 \sigma _1 \left(\log \left(x_1\right)-\mu _1\right) \left(\log \left(x_2\right)-\mu _2\right)+\sigma _1^2 \left(\log \left(x_2\right)-\mu _2\right){}^2+\sigma _2^2 \left(\log \left(x_1\right)-\mu _1\right){}^2}{2 \left(\rho ^2-1\right) \sigma _1^2 \sigma _2^2}\right)}{2 \pi x_1 x_2 \sqrt{-\left(\left(\rho ^2-1\right) \sigma _1^2 \sigma _2^2\right)}}\)
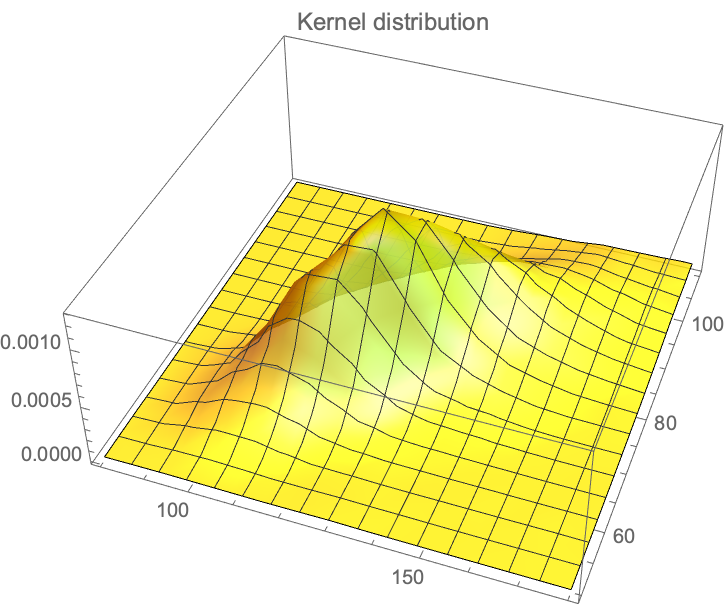
We have the data from the Framingham database for, using \(X_1\) for the systolic and \(X_2\) for the diastolic, with \(n=4040, Y_1= \log(X_1), Y_2=\log(X_2): {\mu_1=4.87,\mu_2=4.40, \sigma_1=0.1575, \sigma_2=0.141, \rho= 0.7814}\), which maps to: \({m_1=132.35, m_2= 82.89, s_1= 22.03, s_2=11.91}\).
In Yalta, K., Ozturk, S., & Yetkin, E. (2016). “Golden Ratio and the heart: A review of divine aesthetics”,
In Yalta, K., Ozturk, S., & Yetkin, E. (2016). “Golden Ratio and the heart: A review of divine aesthetics”,
